 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Few-Step Distillation and Low-Bit Quantization for Wan2.2 Dual-Expert Video Diffusion Models
May 30, 2026Large video diffusion models achieve strong visual quality but remain expensive to deploy because each sample requires many denoising steps and a large resident parameter footprint. This paper studies a deployment-oriented compression pipeline for Wan2.2-T2V-A14B by combining few-step distribution-matching distillation with low-bit quantization. The pipeline follows the model's dual-expert denoising route, calibrates the high-noise and low-noise branches separately, protects sensitive entrance layers, and uses HiF4-style low-bit representation to improve dynamic-range coverage. Quantization is calibrated on the distilled few-step student rather than on the original long-step trajectory, reducing activation-distribution mismatch during inference. The proposed co-design keeps the quantized model close to the same-step full-precision model and surpasses the original full-precision baseline at 8 and 20 steps on average. The 20-step setting gives the best quality-efficiency trade-off in the tested configurations.
QuantSR+: Pushing the Limit of Quantized Image Super-Resolution Networks
May 21, 2026Low-bit quantization is widely used to compress super-resolution (SR) models and reduce storage and computation costs for deployment on resource-limited devices. However, when SR models are pushed to ultra-low precision (2-4 bits), performance can drop sharply due to diminished representational capacity and the detail-sensitive nature of SR. To address these issues, we propose QuantSR+, a unified framework that improves quantization operators, network design, and training optimization, achieving better trade-offs between accuracy and efficiency than prior low-bit SR methods. QuantSR+ mainly relies on three technical contributions: (1) Redistribution-driven Bit Determination (RBD), which reshapes quantization distributions in both forward and backward passes to preserve representation fidelity; (2) Quantized Slimmable Architecture (QSA), which begins with an over-parameterized model and progressively prunes less critical blocks to meet efficiency budgets while pushing the accuracy performance; and (3) Slimming-guided Function-localized Distillation (SFD), which enforces block-aware feature alignment via a direct loss and a progressive, function-local training schedule to capture quantization effects better and speed up convergence. Extensive experiments show that QuantSR+ achieves state-of-the-art performance against both specialized quantized SR methods and generic quantization approaches. For SwinIR-S on Urban100 (x4), it improves PSNR by 0.29 dB over the 2-bit SOTA baseline. Meanwhile, it delivers strong efficiency gains at 2-bit, reducing operations by up to 87.9% and storage by 89.4%. QuantSR+ is effective for both convolutional and transformer-based SR models, indicating broad applicability.
BWTA: Accurate and Efficient Binarized Transformer by Algorithm-Hardware Co-design
Apr 05, 2026Ultra low-bit quantization brings substantial efficiency for Transformer-based models, but the accuracy degradation and limited GPU support hinder its wide usage. In this paper, we analyze zero-point distortion in binarization and propose a Binary Weights & Ternary Activations (BWTA) quantization scheme, which projects tiny values to zero and preserves the accuracy of extremely low-bit models. For training, we propose Smooth Multi-Stage Quantization, combining a Levelwise Degradation Strategy and a Magnitude-Alignment Projection Factor to enable stable and fast convergence. For inference, we develop a BWTA MatMul CUDA kernel with instruction-level parallel bit-packing and comprehensive binary/ternary MatMul implementations for both linear and attention operators, allowing seamless integration across Transformer architectures. Experiments show that BWTA approaches full-precision performance for BERT, with an average 3.5% drop on GLUE and less than 2% drop on five tasks, and achieves comparable perplexity and accuracy for LLMs. In efficiency, it delivers 16 to 24 times kernel-level speedup over FP16 on NVIDIA GPUs, and 216 to 330 tokens/s end-to-end prefill speedup with lower memory footprint on LLMs. As an algorithm-hardware co-design, BWTA demonstrates practical, low-latency ultra-low-bit inference without sacrificing model quality.
Diagonal-Tiled Mixed-Precision Attention for Efficient Low-Bit MXFP Inference
Apr 05, 2026Transformer-based large language models (LLMs) have demonstrated remarkable performance across a wide range of real-world tasks, but their inference cost remains prohibitively high due to the quadratic complexity of attention and the memory bandwidth limitations of high-precision operations. In this work, we present a low-bit mixed-precision attention kernel using the microscaling floating-point (MXFP) data format, utilizing the computing capability on next-generation GPU architectures. Our Diagonal-Tiled Mixed-Precision Attention (DMA) incorporates two kinds of low-bit computation at the tiling-level, and is a delicate fused kernel implemented using Triton, exploiting hardware-level parallelism and memory efficiency to enable fast and efficient inference without compromising model performance. Extensive empirical evaluations on NVIDIA B200 GPUs show that our kernel maintains generation quality with negligible degradation, and meanwhile achieves significant speedup by kernel fusion. We release our code at https://github.com/yifu-ding/MP-Sparse-Attn.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
AFTER: Mitigating the Object Hallucination of LVLM via Adaptive Factual-Guided Activation Editing
Jan 05, 2026Large Vision-Language Models (LVLMs) have achieved substantial progress in cross-modal tasks. However, due to language bias, LVLMs are susceptible to object hallucination, which can be primarily divided into category, attribute, and relation hallucination, significantly impeding the trustworthy AI applications. Editing the internal activations of LVLMs has shown promising effectiveness in mitigating hallucinations with minimal cost. However, previous editing approaches neglect the effective guidance offered by factual textual semantics, thereby struggling to explicitly mitigate language bias. To address these issues, we propose Adaptive Factual-guided Visual-Textual Editing for hallucination mitigation (AFTER), which comprises Factual-Augmented Activation Steering (FAS) and Query-Adaptive Offset Optimization (QAO), to adaptively guides the original biased activations towards factual semantics. Specifically, FAS is proposed to provide factual and general guidance for activation editing, thereby explicitly modeling the precise visual-textual associations. Subsequently, QAO introduces a query-aware offset estimator to establish query-specific editing from the general steering vector, enhancing the diversity and granularity of editing. Extensive experiments on standard hallucination benchmarks across three widely adopted LVLMs validate the efficacy of the proposed AFTER, notably achieving up to a 16.3% reduction of hallucination over baseline on the AMBER benchmark. Our code and data will be released for reproducibility.
Context as a Tool: Context Management for Long-Horizon SWE-Agents
Dec 26, 2025Agents based on large language models have recently shown strong potential on real-world software engineering (SWE) tasks that require long-horizon interaction with repository-scale codebases. However, most existing agents rely on append-only context maintenance or passively triggered compression heuristics, which often lead to context explosion, semantic drift, and degraded reasoning in long-running interactions. We propose CAT, a new context management paradigm that elevates context maintenance to a callable tool integrated into the decision-making process of agents. CAT formalizes a structured context workspace consisting of stable task semantics, condensed long-term memory, and high-fidelity short-term interactions, and enables agents to proactively compress historical trajectories into actionable summaries at appropriate milestones. To support context management for SWE-agents, we propose a trajectory-level supervision framework, CAT-GENERATOR, based on an offline data construction pipeline that injects context-management actions into complete interaction trajectories. Using this framework, we train a context-aware model, SWE-Compressor. Experiments on SWE-Bench-Verified demonstrate that SWE-Compressor reaches a 57.6% solved rate and significantly outperforms ReAct-based agents and static compression baselines, while maintaining stable and scalable long-horizon reasoning under a bounded context budget.
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025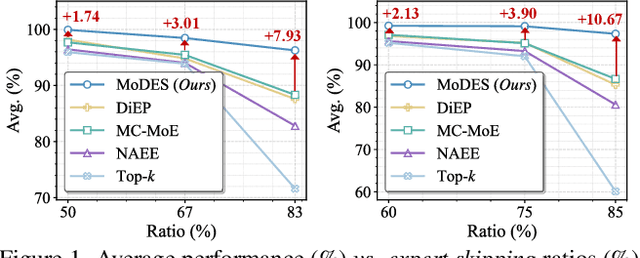
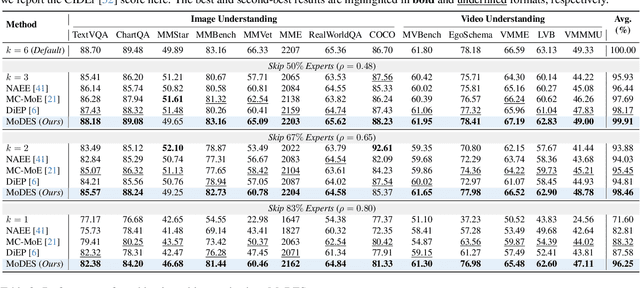
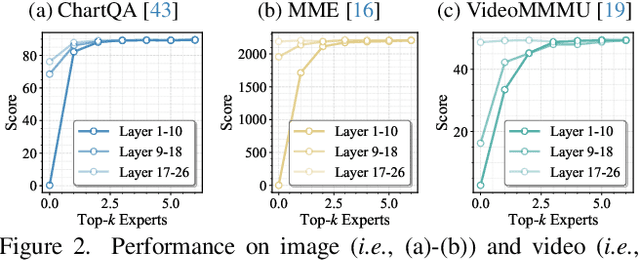
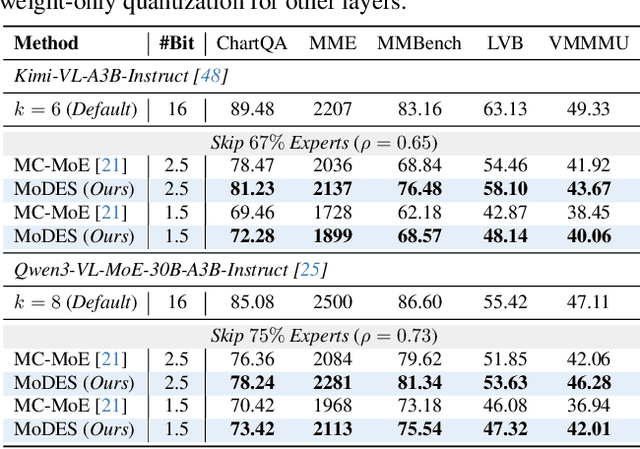
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
SLMQuant:Benchmarking Small Language Model Quantization for Practical Deployment
Nov 17, 2025Despite the growing interest in Small Language Models (SLMs) as resource-efficient alternatives to Large Language Models (LLMs), their deployment on edge devices remains challenging due to unresolved efficiency gaps in model compression. While quantization has proven effective for LLMs, its applicability to SLMs is significantly underexplored, with critical questions about differing quantization bottlenecks and efficiency profiles. This paper introduces SLMQuant, the first systematic benchmark for evaluating LLM compression techniques when applied to SLMs. Through comprehensive multi-track evaluations across diverse architectures and tasks, we analyze how state-of-the-art quantization methods perform on SLMs. Our findings reveal fundamental disparities between SLMs and LLMs in quantization sensitivity, demonstrating that direct transfer of LLM-optimized techniques leads to suboptimal results due to SLMs' unique architectural characteristics and training dynamics. We identify key factors governing effective SLM quantization and propose actionable design principles for SLM-tailored compression. SLMQuant establishes a foundational framework for advancing efficient SLM deployment on low-end devices in edge applications, and provides critical insights for deploying lightweight language models in resource-constrained scenarios.
LLMC+: Benchmarking Vision-Language Model Compression with a Plug-and-play Toolkit
Aug 13, 2025Large Vision-Language Models (VLMs) exhibit impressive multi-modal capabilities but suffer from prohibitive computational and memory demands, due to their long visual token sequences and massive parameter sizes. To address these issues, recent works have proposed training-free compression methods. However, existing efforts often suffer from three major limitations: (1) Current approaches do not decompose techniques into comparable modules, hindering fair evaluation across spatial and temporal redundancy. (2) Evaluation confined to simple single-turn tasks, failing to reflect performance in realistic scenarios. (3) Isolated use of individual compression techniques, without exploring their joint potential. To overcome these gaps, we introduce LLMC+, a comprehensive VLM compression benchmark with a versatile, plug-and-play toolkit. LLMC+ supports over 20 algorithms across five representative VLM families and enables systematic study of token-level and model-level compression. Our benchmark reveals that: (1) Spatial and temporal redundancies demand distinct technical strategies. (2) Token reduction methods degrade significantly in multi-turn dialogue and detail-sensitive tasks. (3) Combining token and model compression achieves extreme compression with minimal performance loss. We believe LLMC+ will facilitate fair evaluation and inspire future research in efficient VLM. Our code is available at https://github.com/ModelTC/LightCompress.